
LabVIEWでAIによる画像処理を使う
はじめに
おそらくこの記事を読んでいる方はLabVIEWを使ったことがある、ある程度理解されている方だと思います。
LabVIEWは色々な計測制御メーカーが自社製品/ライブラリのVI版をリリースしていることが多いですが、ことマシンビジョンとなると、カメラをサポートするVIはあっても画像処理ライブラリのVIサポートはほとんどありません。
NIからはVisionというライブラリとそれを補佐するVision Assistantというツールが提供され、基本的な画像処理の記述は可能ですが、速度面、精度面で画像処理メーカーのライブラリと比べると、どうしても見劣りしてしまいます。また、基本的な画像処理ロジックしかないため、画像処理に精通していないと、要求される処理を構築できません。
そこで、画像処理メーカーの画像処理ライブラリをVI化しようというのが本記事の趣旨です。
今回は、Cognex社のViDi(最新のバージョンはVisionPro Deep Learningに名称が変更されていますが、本記事ではViDiで通します)という、AIによる画像処理ソフトウェアを呼び出すためのVIの作成をしていこうと思います。開発環境はLabVIEW2020を使用しますがLabVIEW2016以降であれば問題ないと思います。
なお、ViDi(VisionPro Deep Learning)は弊社で取り扱っておりますので、ご興味のある方はこちらまでお問合せください。
なお、例示するVIは処理の概要を記述していますので、そのまま書き写しても動作しませんのであらかじめご了承ください。
ViDiを知る
ViDiを使う!といったものの「ViDiって何?」という方もいると思います。
ViDiを端的に説明しますと、従来の画像処理(ルールベースの画像処理)では検出できなかった欠陥(複雑な模様の中の欠陥など)を、AI(Deeplearning)技術を用いて検出可能とする、AIによる画像学習/推論ソフトウェアとなります。学習をするためのツール類と、推論を行うためのライブラリから構成されます。詳細は「Cognex VisionPro Deep Learing」もしくは「ViDiツール」の「ViDi〜ツール」の項を参照ください。
推論を行うためのライブラリは.NET Framework 4.7.xをサポートしている開発環境が必要となります。よって、.NET Frameworkの利用経験がない場合は難しいかもしれません。
LabVIEWにおいては、.NET Frameworkは「.NET」カテゴリのVIを使用することで実装が可能です。これについては、業務上で.NET Frameworkや.NETのライブラリDLLを呼び出した経験のある方は理解できると思います。
ViDiの流れ
ViDiを用いた推論の流れは以下の通りとなります。
- ViDiを初期化
- ランタイムワークスペース(1つ以上の、推論のための学習済みデータを格納したデータ構造)ファイルを読み込む
- ワークスペースから、使用する学習済みデータを取り出す
- 画像データを引数として、推論を実行する
- 推論結果を取り出し、データ化する
- ワークスペースをメモリから解放する
手順そのものはシンプルではありますが、学習を除けば、4の推論結果を取り出してデータ化するのが煩雑な部分となります。
1.ViDiの初期化
まずはViDiの初期化を行います。これはアプリケーション起動時に一度だけ実行するものです。
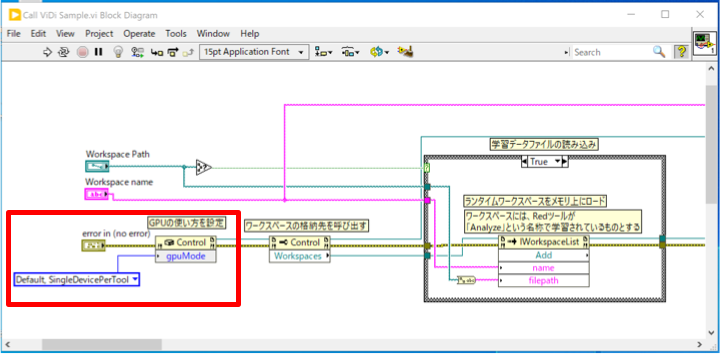
赤枠の部分が初期化処理です。非常にシンプルです。コンストラクタノードにて「ViDi2.Runtime.Local.Control」クラスを指定し、リファレンスを取得します。オプションで、GPUの使用方法を選択します(複数のGPUを使用している場合。1つのみの場合は指定する必要はありません)
2.ランタイムワークスペースファイルを読み込む
次に、推論用の学習済みデータを読み込みます。
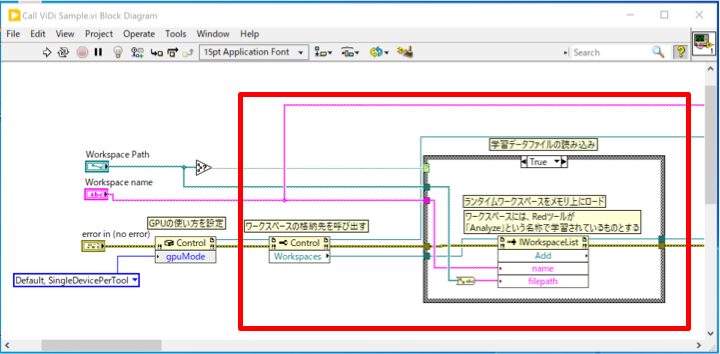
先ほどのリファレンスにプロパティノードを接続し、「Workspaces」プロパティ(ViDi2.Runtime,IWorkspaceList)を取得します。
ワークスペースファイルは複数の学習済みデータを格納できる、としましたが、「Workspaces」プロパティはさらに複数のワークスペースファイルを格納することが可能です(もちろん、メモリの許す範囲で)。
Workspacesのリファレンスにインボークノードを繋ぎ、「Add」を呼び出します。これの「filepath」にワークスペースファイルのファイルパスを、「name」にその名称を与えることで、ワークスペースファイルを読み込みます。
3.ワークスペースから、使用する学習済みデータを取り出す
次に、推論で使用する、学習済みデータを取り出します。
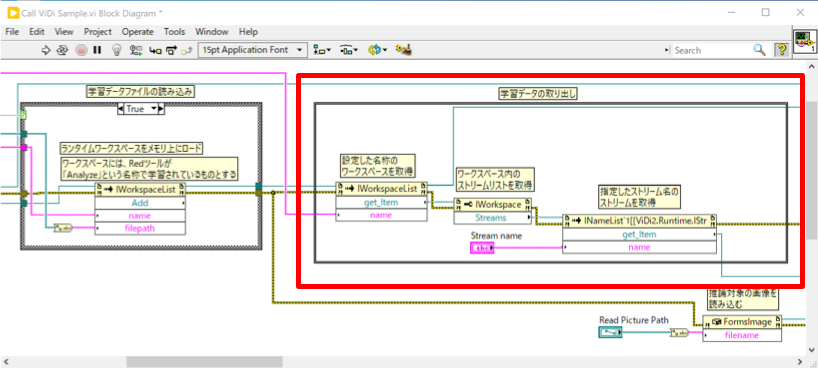
Workspacesのリファレンスにインボークノードを繋ぎ、「get_Item」を呼び出します。その際に「name」に、先ほどAddで指定した名称を与えます。
それにより、nameに紐づけられたワークスペースデータ(ViDi2.Runtime.IWorkspace)が取得できます。
さらに、get_Itemで取得したリファレンスにプロパティノードを接続し、「Streams」プロパティを取得します。
先に、ワークスペースには1つ「以上」の学習済みデータが格納、と書きましたが、この「Streams」がそれらを複数の学習済みデータを格納するしくみとなります。
そこから特定の学習済みデータを取り出すのは、先ほどのワークスペースの時と同様に「Streams」のリファレンスからインボークノードを接続し、「get_Item」で取り出します。この際、「name」を指定しますが、学習データが1つのみでかつ、名称を変更していなければ「default」となっていますので、通常はnameに「default」を指定します。
これで、ようやく学習済みデータ(ViDi2.Runtime.IStream)が取得できます。
4.画像データを引数として、推論を行う
まず、画像データを読み込みます。
形式はViDi独自のものとなります。ここではViDi2.FormsInageを使用し、画像ファイルを読み込み、それをViDi2.IImageに型変換を行い、渡します。
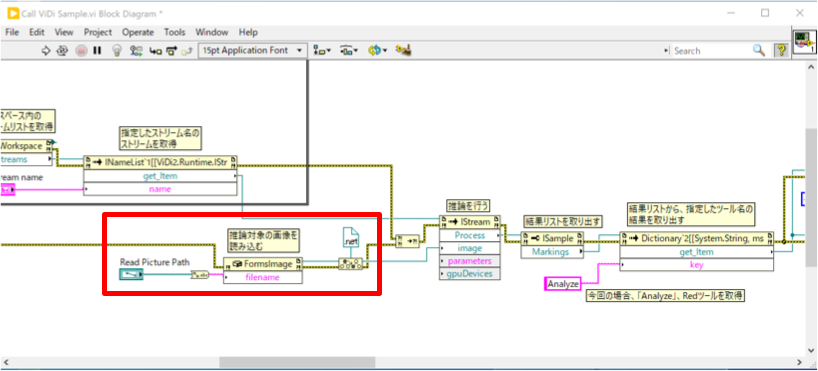
3.にて取り出した学習データのリファレンスにインボークノードを接続し、「Process」インボークを呼び出します。引数には画像データを渡します。
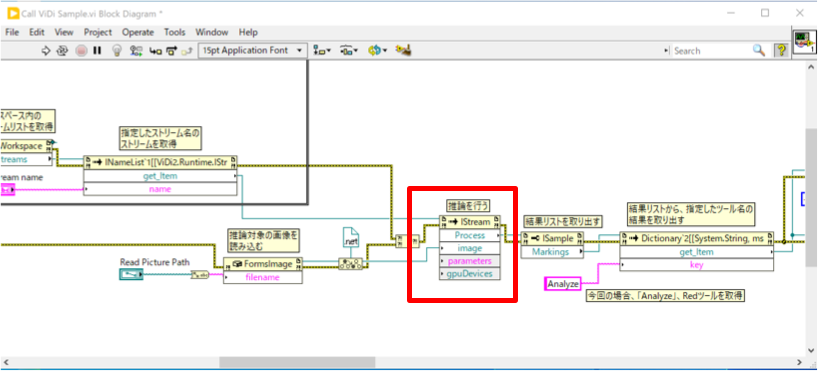
5.推論結果を取得し、データ化する
「Process」インボークの結果は「ViDi2.ISample」という形式で返され、そのプロパティの「Markings」に推論結果の詳細が格納されています。
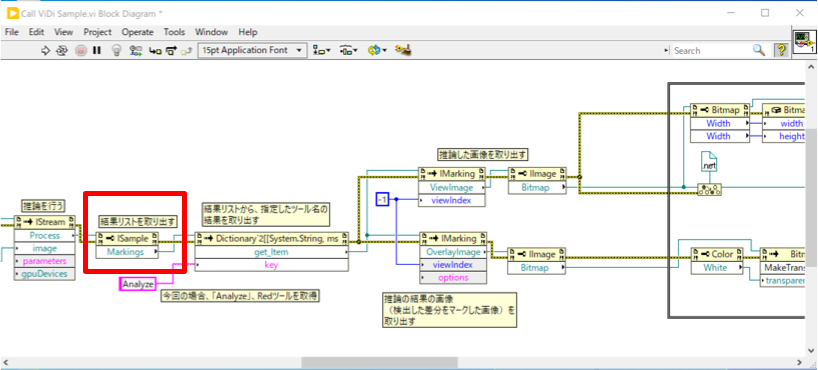
そこから「get_Item」インボークを使用して「Analyze」という名称の推論結果を取得します。これは「Red Analyzeツール」という、特徴検出ツールのデフォルト名称となります。
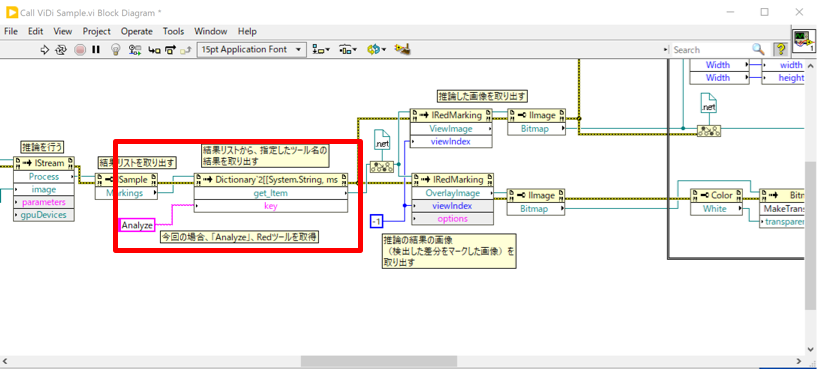
推論結果(ViDi.IMarking)には、学習データと差異のある部分の得点(学習データからどのくらい異なるかを数値で示したもの)、座標、面積などが格納されています。
得点の数値と、あらかじめ決めた閾値との比較により、その特徴が欠陥であるかそうでないかを判断することになります。
サンプルVIでは、差異のデータを画像化した「OverlayImage」と元画像「ViewImage」を取得しています。Red Analyzeツールの結果を取得するため、IMarkingからIRedMarkingへ型変換をしてから画像を取得しています。
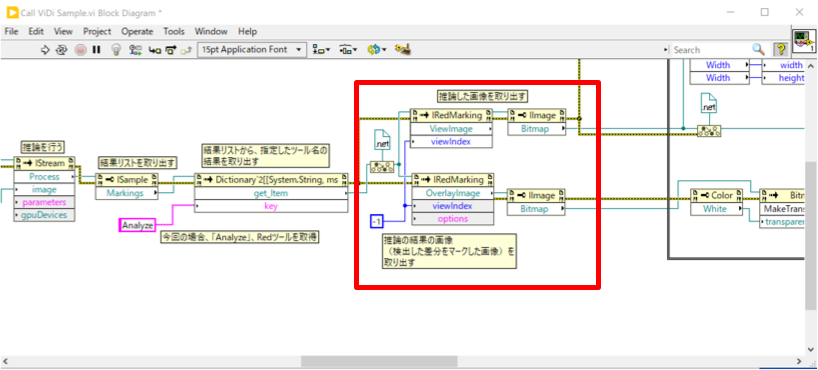
それらを合成し、元画像のどこに欠陥があるかを示すようにして、ファイル保存しています。
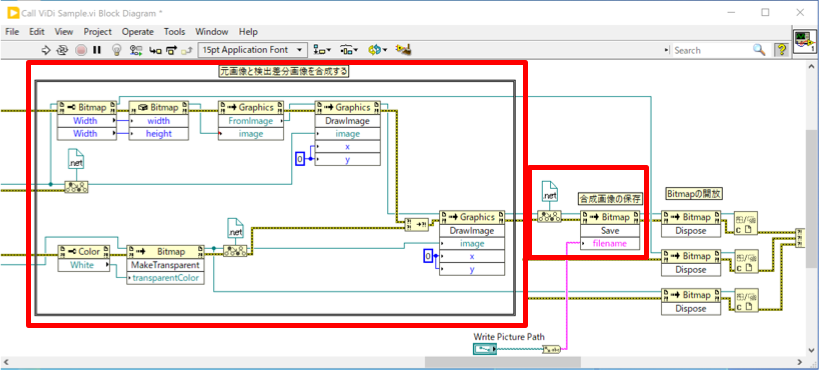
保存の際には.NETのBitmapクラスに変換していますので、それをさらにLabVIEWのImage形式に変換して表示する形になると思います。
最後に、作成したメモリ上の画像データを解放します。
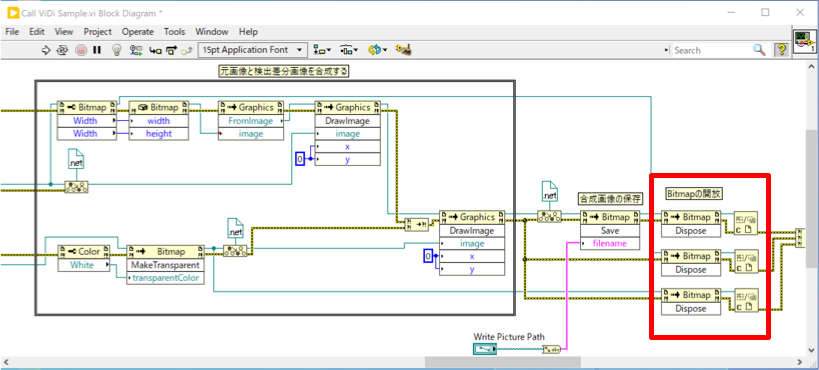
6.ワークスペースをメモリから解放する
全ての推論が終了し、アプリケーションを修了する際には、ワークスペースをメモリから解放します。
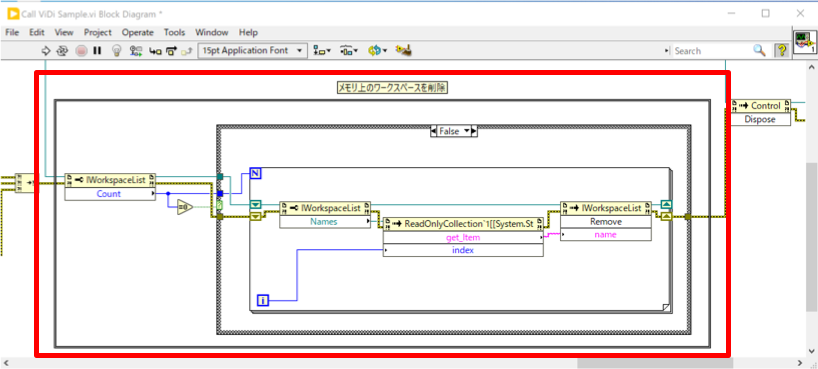
これはWorkspacesに格納されているワークスペースの数分、ワークスペースの名称を取得し、それを引数として「Remove」インボークを呼び出す形になります。
ざっくりとですが、以上でViDiを使うためのVIの構築の方法となります。
実際の構築時には、.NET VIでの参照設定に使用するViDiのライブラリの名前空間やクラス名が必要となりますが、ViDiのリファレンスを参照ください。
おわりに
繰り返しになりますが、.NET Frameworkや、.NETベースのDLLをLabVIEWから呼び出した経験のある方であれば、VIの構築はそれほど難しくないかと思います。
万一、自身でVIの構築が難しい場合は構築済みのVIの提供(有償となりますが)も可能ですので、ご相談ください。
